Automated Vulnerability Remediation Best Practices

Modern vulnerability management has outgrown manual workflows and static severity scores. Today’s environments demand automated remediation that operates at scale while safeguarding business continuity, factoring in application dependencies, legacy platforms, and changing risk before action is taken.
This article outlines best practices for designing and operating automated vulnerability remediation for enterprises and service providers, with a focus on reducing risk, cutting noise, and eliminating repetitive manual effort.
The guidance in this article applies to automated vulnerability remediation platforms designed to operate across complex, heterogeneous environments. These systems typically integrate broad telemetry collection, threat intelligence enrichment, policy-driven prioritization, and controlled remediation automation across endpoints, servers, cloud workloads, and network devices.
These best practices are relevant for use cases such as continuous vulnerability management, exploit-driven triage, large-scale patching, organization-wide remediation, and reducing mean time to remediate (MTTR) in production environments. They are not intended to replace manual penetration testing, red-team operations, or highly bespoke, one-off remediation scenarios that require deep application-specific redesign.
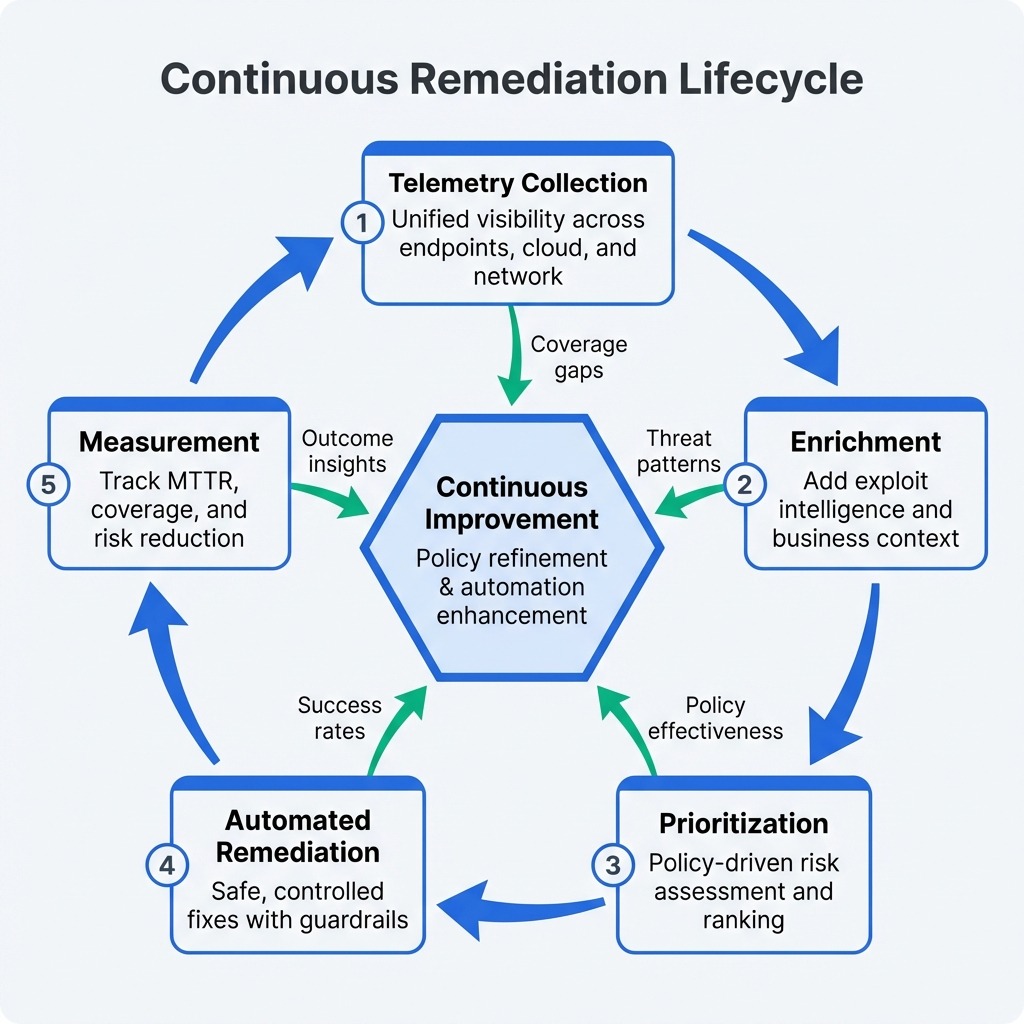
As depicted above, an end-to-end, continuous cycle that begins with real-time telemetry, enriches and prioritizes findings based on risk, executes automated remediation, and feeds outcomes back into continuous measurement. We will discuss these in more detail in this article.
{{banner-small-2="/inline-cards"}}
Summary of key automated vulnerability remediation concepts
Establish comprehensive and reliable security telemetry
Automated vulnerability remediation is built on the telemetry that informs it. If your visibility is fragmented or incomplete, automation will either miss critical exposures or apply fixes based on inaccurate assumptions. For MSSPs operating at scale, a strong telemetry foundation is essential to consistently detect, prioritize, and remediate vulnerabilities across diverse customer environments.
In real-world MSSP environments, vulnerabilities rarely exist in isolation. A missing OS patch becomes materially riskier when the asset is reachable due to permissive firewall rules or when adjacent devices with outdated firmware enable alternate attack paths. Comprehensive telemetry allows remediation workflows to correlate these signals and apply the right fix, not just the fastest one.
Effective telemetry enables:
- Accurate asset discovery across hybrid and multi-cloud environments
- High-confidence vulnerability detection
- Context-aware remediation decisions
- Reduced false positives and failed fixes
The following specific practices are recommended for building a strong telemetry foundation.
Use a single, unified collection mechanism
Deploying multiple agents for different data sources increases operational overhead, performance impact, and failure points. MSSPs should favor a single, lightweight agent or a unified collection pipeline wherever possible.
Ensure full coverage across the environment
Telemetry should extend beyond traditional endpoints to include all infrastructure components that influence security posture. Here are some examples of data sources to include:
- Endpoints and servers (e.g., Windows, Linux, and macOS)
- Identity and access systems (e.g., IAM platforms, Active Directory, and identity providers)
- Cloud workloads (e.g., VMs, containers, and managed services)
- Network devices (e.g., routers, switches, firewalls, and load balancers)
- IoT and specialized devices (e.g., OT, embedded systems, and appliances)
- Mobile and device management platforms (MDMs) for managed laptops, mobile devices, and enforcement status
Collect both configuration and runtime data
Configuration data alone (e.g., “port 22 is open”) does not tell the full story. Runtime data (e.g., “port 22 is actively accepting external connections”) adds critical context. Some examples of valuable telemetry are:
- OS and application patch levels
- Installed packages and versions
- Open ports and listening services
- Active processes and network connections
- Network device firmware and rule sets
Normalize gathering telemetry early
Raw telemetry from different platforms often uses inconsistent formats, naming conventions, and severity definitions. Normalizing data as early as possible simplifies downstream automation and analytics.
The table below shows various areas where telemetry is typically collected, with examples.
{{banner-small-3="/inline-cards"}}
Enrich vulnerability data with threat and business context
Raw vulnerability scan results are noisy by nature: A typical MSSP may ingest tens of thousands of CVEs across customer environments, many of which pose little real-world risk. Without enrichment and appropriate guardrails, automated remediation can lack the context needed to apply fixes appropriately and lead to both overly aggressive actions and missed remediation opportunities. Enrichment bridges this gap by turning technical findings into actionable, risk-aware intelligence.
Automation decisions should be driven by the likelihood of exploitation and business impact, not just CVSS scores. A medium-severity CVE with an active exploit on a production system may be far more dangerous than a critical CVE on an isolated test server. Enrichment provides the context needed to make these distinctions automatically and consistently.
The following best practices are recommended for vulnerability enrichment.
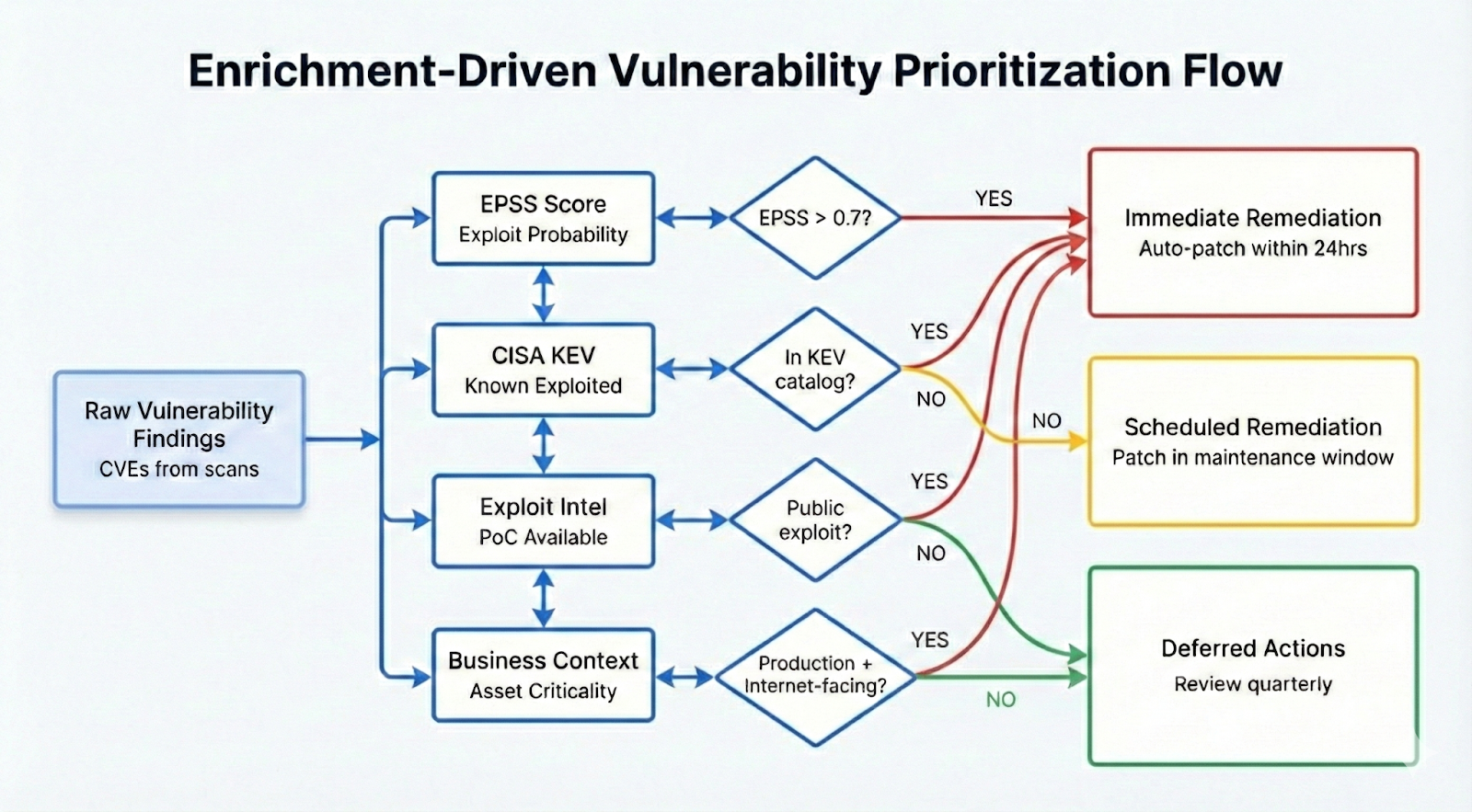
Correlate findings with exploit intelligence
Not all vulnerabilities are exploited in the wild. MSSPs should integrate external threat intelligence to understand which CVEs are actively weaponized or likely to be exploited. Here are some typical enrichment sources:
- EPSS: Estimates the likelihood that a vulnerability will be exploited in the real world within a given time frame, helping teams prioritize based on probability rather than severity alone.
- CISA KEV: Identifies vulnerabilities that are confirmed to be actively exploited in the wild, serving as a high-confidence signal for immediate remediation.
- ExploitDB: Catalogs publicly available exploit code, indicating that exploitation techniques are known and accessible to attackers.
- GitHub PoCs: Highlights vulnerabilities with proof-of-concept code that is actively developed or maintained, signaling increasing exploit maturity and practical risk.
Attach business and asset metadata
Technical severity alone is insufficient for prioritization. Every asset should carry a business context that influences remediation urgency. Here are some examples of metadata attributes:
- Business criticality (low, medium, high)
- Data sensitivity (PII, PHI, financial)
- Environment (production, staging, development)
- Asset owner or responsible team
- Internet exposure (public vs. internal)
When combined with vulnerability data, this metadata enables risk-based automation aligned with customer priorities.
Continuously refresh enrichment data
Exploitability is not static: A vulnerability that appears low risk today can quickly become critical once a public proof of concept or exploit is released. As the threat landscape shifts, MSSP platforms must continuously reassess risk rather than relying on a one-time evaluation at discovery.
To stay effective, platforms should periodically re-evaluate signals such as EPSS scores and CISA KEV status, detect newly published PoCs or exploit references, and automatically retrigger prioritization and remediation workflows when risk materially changes. Continuous enrichment ensures that automation remains accurate, timely, and aligned with real-world attacker behavior.
Treat enrichment as a first-class input
Enrichment should not be treated as an afterthought or limited to reporting alone; it must directly drive operational decisions across the vulnerability lifecycle. Signals from enrichment should influence how vulnerabilities are prioritized, how SLAs are assigned, whether issues qualify for automated remediation, and when escalation or approval workflows are triggered. Effective automation explicitly references these contextual signals rather than relying solely on raw scan output, so actions are aligned with real risk and business impact.
Example: Context-driven escalation of a critical CVE
An MSSP identifies a critical vulnerability on a customer’s production web application server, such as CVE-2024-23897, a Jenkins remote file read vulnerability that was widely exploited shortly after disclosure. Enrichment shows an extremely high risk profile: an EPSS score of 0.92, indicating a strong likelihood of exploitation, inclusion in CISA’s Known Exploited Vulnerabilities (KEV) catalog, and readily available public exploits on ExploitDB and GitHub. The affected asset is internet-facing, supports a revenue-generating service, and handles sensitive customer payment data, significantly increasing potential business impact.
Based on this context, the automation platform elevates the issue to the highest priority and initiates immediate risk-reduction actions that avoid production disruption. This may include deploying pre-approved compensating controls such as web application firewall (WAF) rules, access restrictions, or configuration hardening to block known exploit paths, while automatically scheduling or recommending a controlled maintenance window for permanent patching. Both the customer and analysts are notified of the mitigation applied and the planned remediation, reducing exposure from days to minutes without causing an unplanned outage.
Without enrichment, this CVE might have been buried among thousands of others. With it, automation responds decisively and safely.
Implement policy-driven automated prioritization
Not every vulnerability warrants the same level of urgency. In large-scale MSSP operations, treating all findings equally quickly overwhelms analysts and erodes confidence in automation. Policy-driven prioritization addresses this challenge by replacing static, severity-only workflows with flexible decision logic that reflects real risk and customer expectations.
At the core of this approach is a policy engine that determines which vulnerabilities should generate alerts, enter remediation queues, or trigger fully automated fixes. Instead of relying solely on CVSS scores, policies evaluate vulnerabilities through multiple dimensions, allowing automation to behave predictably and defensibly.
Effective prioritization policies combine exploitability signals, asset criticality, and exposure context into a single risk decision. A vulnerability with an available exploit and high likelihood of exploitation may be elevated automatically, while the same CVE on an internal or non-critical system can be deferred. Multi-factor evaluation ensures that remediation efforts are proportional to actual risk rather than theoretical severity.
Policy engines also play a critical role in suppressing noise. Low-risk findings that fall below defined thresholds can be deprioritized, temporarily suppressed, or scheduled for remediation during maintenance windows. This prevents automation from repeatedly surfacing issues that do not materially affect security posture, freeing teams to focus on high-impact work.
Example of policy-driven prioritization
An MSSP defines a prioritization policy for internet-facing production systems that process sensitive data. When the platform detects CVE-2023-34362 (the MOVEit Transfer SQL injection vulnerability), the policy engine evaluates more than just its high CVSS score. It considers that the CVE has a public exploit, is actively exploited in the wild, carries a high EPSS score, and affects a customer-facing file transfer service marked as business-critical and exposed to the internet. Based on these combined signals, the policy automatically elevates the finding to critical, bypasses standard remediation queues, triggers an approved mitigation, and alerts both the customer and on-call analysts.
Perform root-cause analysis to eliminate vulnerability clusters
In large-scale MSSP operations, vulnerabilities are rarely isolated events. They are usually symptoms of a deeper issue, such as an outdated library, a vulnerable base image, or a misconfigured service propagated across environments. Remediating findings individually becomes inefficient at scale, while addressing issues at the source reduces duplicate effort and allows regression risk to be managed through controlled rollouts and rollbacks. Root-cause remediation addresses this by eliminating the underlying source of risk once and at scale.
The following practices are recommended for root cause analysis in the context of vulnerability remediation.
Group vulnerabilities by source
A fundamental best practice is grouping vulnerabilities based on where they originate rather than treating them as independent CVEs. Findings should be clustered by package name, service, container image, configuration template, or infrastructure module. This grouping quickly reveals patterns that would otherwise be hidden in long vulnerability lists and helps automation reason about why issues exist, not just where they appear.
Identify shared dependencies across assets
Modern environments rely heavily on shared dependencies, particularly in containerized and cloud-native architectures. A single vulnerable library may be embedded in multiple applications, images, or virtual machines. Identifying these shared dependencies allows MSSPs to trace dozens of CVEs back to a common component and avoid redundant remediation actions across individual assets.
Prioritize fixes with the highest blast radius reduction
Once root causes are identified, remediation should prioritize fixes that eliminate the largest number of downstream findings. Addressing a single shared dependency often removes dozens, or even hundreds, of associated vulnerabilities in one controlled change. This approach improves remediation efficiency while reducing operational risk compared to applying many isolated patches.
Feed root cause intelligence into automation logic
Root-cause insights should actively inform remediation and patching workflows. When automated systems understand that vulnerabilities stem from a specific image, package, or configuration, they can target that source directly in future remediation cycles. Over time, this enables preventative remediation, reducing the likelihood that the same vulnerabilities will reappear in subsequent scans.
Automate patching and remediation safely and incrementally
Automation should reduce manual effort without compromising system stability or customer trust. In the MSSP context, effective automated vulnerability remediation focuses on well-scoped, repeatable actions that can be executed confidently at scale. The goal is not to automate everything but to automate the right things, freeing human experts to focus on complex or high-risk scenarios.
The following best practices are recommended for automated patching and remediation.
Start with high-confidence remediation actions
Successful automation begins with remediation tasks that are low-risk and well understood. Operating system patches, package updates, and configuration changes with predictable outcomes are ideal starting points. These actions are common across customer environments and can be reliably validated, making them strong candidates for automation. High-confidence actions include applying non-breaking OS and kernel patches, updating widely used system packages, and restarting services with known-safe behavior.
Apply guardrails to protect stability
Automation must operate within clearly defined guardrails to ensure reliability. Maintenance windows prevent remediation from interfering with business-critical operations, while canary deployments allow fixes to be tested on a subset of systems before broad rollout. Rollback checks ensure that if a remediation action fails or degrades performance, systems can be restored to a known-good state automatically. These controls transform automation from a risky shortcut into a disciplined operational process.
Target partial automation, not full autonomy
Attempting to automate all remediation tasks is neither realistic nor necessary. Many mature remediation programs automate a meaningful share of low-risk, repetitive fixes, with the exact percentage varying based on environment complexity, tenant requirements, and underlying technologies. This balance delivers meaningful efficiency gains while keeping human oversight where judgment and experience are required. The result is faster response to routine vulnerabilities and more analyst time available for complex investigations and edge cases.
Integrate with CI/CD and infrastructure as code (IaC)
Automated remediation becomes significantly more powerful when integrated into CI/CD pipelines and infrastructure-as-code workflows. Fixes applied at build time, such as updating base images or enforcing secure configurations, prevent vulnerabilities from being deployed in the first place. This shifts remediation left, reducing downstream risk and operational load. When automation feeds changes back into version-controlled templates, fixes become repeatable, auditable, and easier to maintain across customer environments.
Example: Controlled patching with automated oversight
An MSSP implements an automated workflow that applies non-breaking kernel and package updates during overnight maintenance windows. Each change is validated through pre- and post-checks, with automatic rollback if issues are detected. Higher-risk updates, such as major kernel upgrades, are flagged for analyst approval before execution.
At the same time, the MSSP leverages a unified agent that collects OS patch state, installed packages, open ports, and network device firmware versions. This telemetry ensures that remediation actions are based on accurate, real-time visibility across customer environments.
{{banner-large-1="/inline-cards"}}
Scale remediation operations for MSPs and MSSPs
MSSPs operate in inherently multi-tenant environments, managing vulnerabilities across hundreds of customer accounts with different risk tolerances, approval models, and compliance requirements. To operate efficiently at this scale, remediation must be centralized, standardized, and measurable, while avoiding the operational burden of tenant isolation or customization.
Follow these practices to make remediation operations scalable.
Centralize visibility and control
A global dashboard provides a single source of truth for vulnerability exposure and remediation status across all customers. Instead of reacting tenant by tenant, MSSPs can identify systemic risks, prioritize widespread threats, and coordinate remediation efforts from a unified control plane. This visibility is especially critical when responding to newly disclosed or actively exploited vulnerabilities.
Scale actions with tenant-aware controls
Bulk remediation capabilities allow MSSPs to act quickly across many environments. However, scale must not compromise isolation. Effective platforms ensure bulk actions respect customer-specific policies such as maintenance windows, approval workflows, and risk thresholds. This approach enables speed while maintaining trust and compliance.
Create reusable remediation playbooks
Standardized remediation playbooks are key to consistency. Common vulnerability classes, such as missing OS patches or insecure configurations, can be addressed using reusable workflows that are applied across customers. Parameterization allows each playbook to adapt to tenant-specific settings while maintaining a uniform remediation process.
Perform SLA and outcome tracking
At scale, remediation effectiveness must be measurable. Tracking SLAs, time to remediate, and success rates across tenants enables MSSPs to demonstrate value, identify operational bottlenecks, and continuously improve automation strategies. This data also supports transparent reporting and customer communications.
The table below outlines core capabilities required to operate automated vulnerability remediation at MSSP scale. Each capability is paired with the operational benefit it delivers to help MSSPs reduce risk efficiently while maintaining customer trust.
Measure outcomes and continuously improve automation
Automated vulnerability remediation is not a “set it and forget it” capability. As customer environments, threat landscapes, and business priorities evolve, automation must be continuously evaluated and refined. Without measurement and feedback loops, remediation risks become busywork, executing actions without delivering meaningful risk reduction.
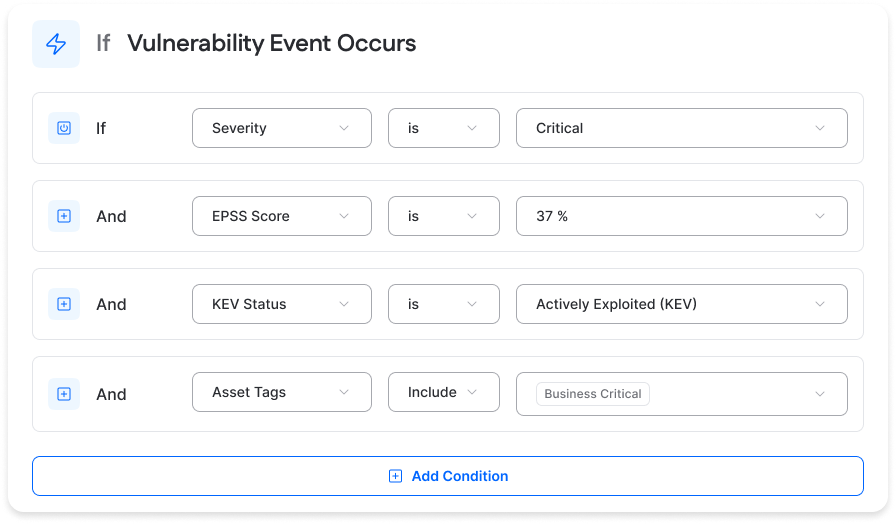
The following are the recommended best practices in this area.
Measure what matters
To understand whether automation is working, MSSPs must track metrics that reflect real security and operational impact. Mean time to remediate (MTTR) is a core indicator of responsiveness, but it should be paired with metrics that show the quality of remediation, such as overall risk reduction and the percentage of vulnerabilities addressed through automation.
Automation coverage, especially how much of the remediation workload is handled without human intervention, provides insight into efficiency gains and helps identify areas where additional automation is viable.
Use failures and noise as signal
False positives and failed remediation attempts are not just errors; they are feedback. Monitoring where automation produces incorrect alerts, unnecessary fixes, or unstable changes helps refine prioritization policies and guardrails. Over time, this tuning improves trust in automation and reduces analyst intervention.
Incorporate human and customer feedback
Automation should reflect both operator experience and customer expectations. Feedback from SOC analysts, SREs, and customer teams often highlights gaps that metrics alone cannot capture, such as business impact, change sensitivity, or operational constraints. Incorporating this feedback into remediation logic ensures automation aligns with real-world usage, not just theoretical risk models.
Reassess policies as environments change
Cloud migrations, new services, and evolving architectures can quickly invalidate earlier assumptions. Prioritization and automation rules should be reviewed regularly to ensure they remain relevant. What was once a low-risk system may become business-critical, and automation must adapt accordingly. Periodic reassessment ensures that remediation remains aligned with both current infrastructure and emerging threats.
Example: Measuring impact at scale
An MSSP expands automated patching for high-confidence OS and package updates while refining prioritization logic to emphasize exploitability signals. Over several months, MTTR drops substantially depending on baseline and changes implemented, with a corresponding decrease in high-risk exposure across customer environments. Continuous monitoring confirms fewer failed remediations and higher customer satisfaction.
{{b-table="/inline-cards"}}
Last thoughts
Automated vulnerability remediation is most effective when it is built on complete telemetry, enriched with real-world threat and business context, and guided by policy-driven prioritization rather than raw severity alone. By focusing on root causes, safely automating high-confidence fixes, and scaling operations through centralized workflows, organizations and MSSPs can dramatically reduce manual effort while improving consistency and speed of response. Ultimately, successful automation is not about fixing everything faster; it’s about fixing the right things, at the right time, in a way that measurably reduces risk across the entire environment.


